
Build a virtual assistant with real-time LLMs
Nov 06, 2023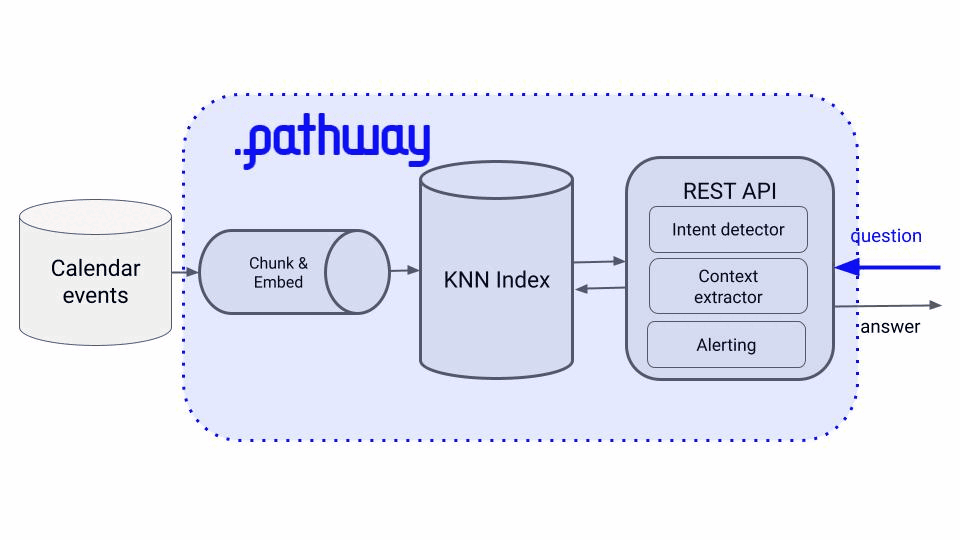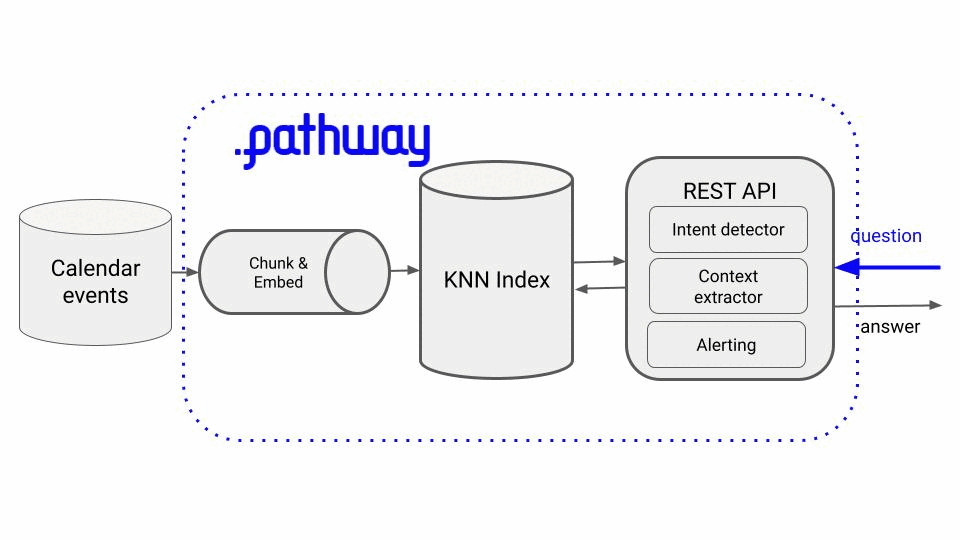
Today I wanna show you step by step, how to build a virtual assistant using LLMs and real-time data processing, using an open-source framework called Pathway.
The end product will NOT be just a demo, but a highly modular and scalable blueprint, that you can adjust for your particular problem and data sources. So you build your first real-world LLM-app.
Let’s get started!
A virtual assistant using LLMs and real-time data processing
The end system you will build will
-
Take your request → “Do I have any meetings tomorrow?”
-
Connect to your calendar data, in real-time
-
Generate a response → “Based on your calendar information, you have a meeting with Paul tomorrow at 14:00“, and
-
Send an alert to your Discord server, whenever there are changes in your calendar.

How do you build this?
To build such app you need to implement 2 pipelines:
-
A real-time data pipeline, that listens to your calendar events in real-time, processes the raw text into numerical vectors, by chunking and embedding, and pushes them to a Vector Store.

-
An inference pipeline, that takes in your request and goes through a sequence of steps, i.e.
-
intent detection
-
context extraction, and
-
alerting if the new system output differs from the previous response.
-

And the thing is, as soon as you start implementing this system, you quickly realize you need to spend too much time building a backbone of infrastructure and data-engineering boilerplate, before you can even work on your business logic.
Which means, you spend too much time on the non-differentiating elements of your product, and not enough on the differentiating ones.
So the question is:
Is there a faster way to build real-world apps using LLMs?
… and the answer is YES!
Say hello to Pathway 👋
Pathway is an open-source framework for high-throughput and low-latency real-time data processing.
Pathway provides the backbone of services and real-time data processing, on top of which you define your business logic in Python. So you focus on the business logic, and let Pathway handle the low-level details and data engineering boiler plate.
So you build real-world LLMOps app, faster.

Example ✨
You can find all the source code of our virtual assistant in this GitHub repository I prepared.
Let’s see how to implement our virtual assistant using Pathway.
import pathway as pwTo build our virtual assistant app with Pathway we need to define the following building blocks:
-
Input connector, to define
-
raw data source → local folder in this case (changing this to a remote storage like S3 or an external database is just one line of code!)
-
schema of this raw data → simple text in this case
-
the frequency at which we want to ingest raw data → real-time in this case.
documents = pw.io.jsonlines.read( data_dir, schema=DocumentInputSchema, mode="streaming", autocommit_duration_ms=50, )
-
-
Embedding model, to define how we want to transform raw chunks of text into numeric vectors. In this case we use the popular OpenAI
text-embedding-ada-002model.embedder = OpenAIEmbeddingModel(api_key=api_key) -
Document indexer, to define how we want to store and retrieve our embeddings. In this case we use a K-nearest neighbor index
index = KNNIndex( enriched_documents.data, enriched_documents, n_dimensions=embedding_dimension ) -
App-specific business logic. In this case we engineer prompts to perform the following tasks.
-
Intent detection → Does the user want to receive alerts in the future if there are changes to the calendar?
def build_prompt_check_for_alert_request_and_extract_query(query: str) -> str: ... -
Response comparison → Has the response to a previous user query changed? If so, send an alert on Discord.
def build_prompt_compare_answers(new: str, old: str) -> str: ...
-
-
Response generation model. In this case we use OpenAI
gpt-3.5-turbomodel = OpenAIChatGPTModel(api_key=api_key) -
Output connector, to receive input requests from users, and send back responses. In this case we use a simple HTTP REST API, with persistence of old queries, to enable response comparison.
query, response_writer = pw.io.http.rest_connector( host=host, port=port, schema=QueryInputSchema, autocommit_duration_ms=50, keep_queries=True, ) -
Notification hook. In this case, I use a webhook to a Discord server.
send_discord_alerts(alerts.message, discord_webhook_url)
Once all the elements are in place, plus a bit of glue code to connect them, you can run your app
pw.run()Here you can find the full source code implementation behind our virtual assistant → See full source code
Next steps 👣
The Pathway framework is very modular, meaning you can easily plug and play different components.
For example, in a more realistic setting, you will not read raw data from a local folder, but from a Kakfa topic, or a remote s3 bucket, and that requires just one-line code change.
# read in real-time from S3 bucket
documents = pw.io.s3.read(...)
# read in real-time from Kafka topic
documents = pw.io.kafka.read(...)Similarly, you can use an open-source LLM API running inside your cloud environment, instead of OpenAI API, to embed text and generate responses.
Now it is your turn 🫵
The only way to learn LLMOps is to build an LLM app yourself.
So I suggest you the following:
-
Git clone this open-source repository with real-world LLM app examples built with Pathway.
-
Give it a star ⭐ on GitHub to support the open-source, and
-
Start building your next LLM-powered app 🚀
What are you planning to build? → Let me know in the comments.
Have fun, and talk to you next week.
Pau
