
How to generate training data for your ML system 🏋️
Jun 17, 2024
In real-world ML projects training data does not magically fall from the sky as in Kaggle. Instead, you have to generate it yourself.
And the truth is, generating this training data takes way more time, effort and debugging than training the ML models later on.
Let me share with you a few tricks to generate good training data, so you can train great ML models, build great ML systems, and become a great ML engineer.
The problem 🤔
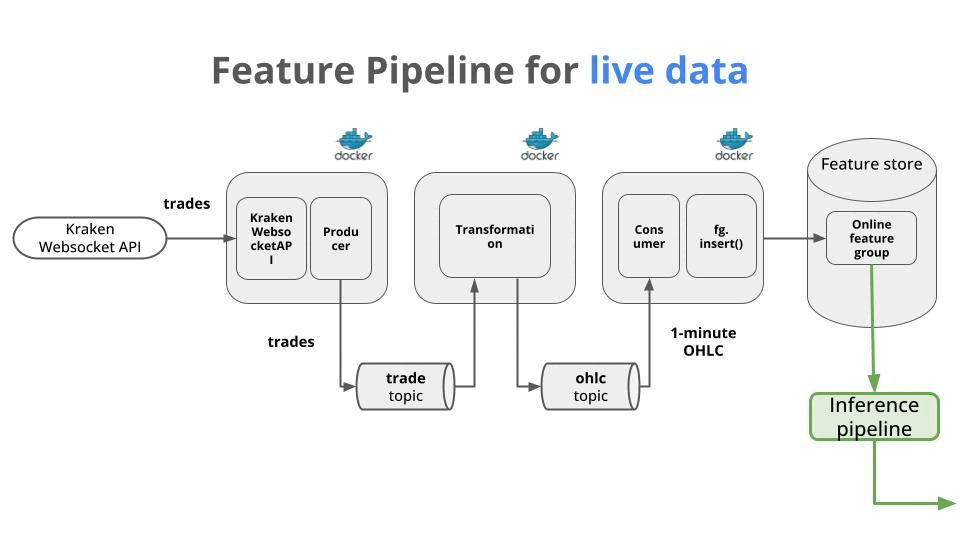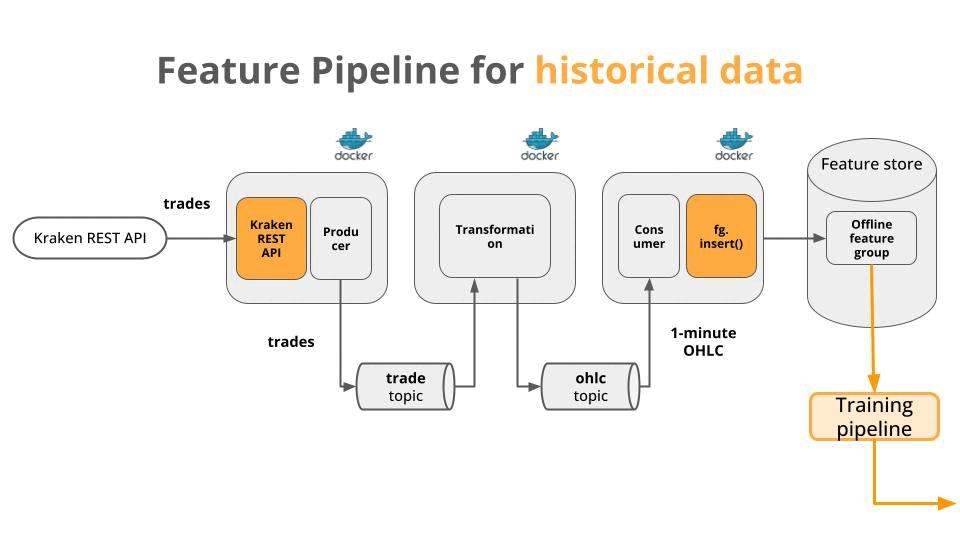
Let’s say you want to build a crypto price predictor, like the one we are building in the “Building a Real-Time ML System. Together”. This system is made of 3 pipelines (aka programs that map predefined inputs to predefined outputs).
→ The feature pipeline, that ingests raw features to ML model features in real-time and outputs them to the Feature Store.
→ The training pipeline, that ingests training data from the Feature Store and outputs the trained model to the model registry.
→ The inference pipeline that loads the model from the registry, ingests real-time features from the Feature Store, and outputs fresh predictions in real-time.

To build this system you start with the feature pipeline ↓

In this case, it is a real-time feature pipeline, that runs 24/7 and does 3 things:
-
ingests raw trades from the Kraken Websocket API.
-
transforms these trades into OHLC candles in real-time using a Python library like Quix Streams.
-
saves these OHLC feature into the Feature Store.
Each of these steps is implemented as an independent dockerized Python microservice, and data flows between them through a message broker like Apache Kafka/Redpanda/Google PubSub. This design makes the system production-ready and scalable from day 1.

Once you have the feature pipeline up and running, features start flowing to your Feature Store. From there, they can be consumed by the other 2 pipelines: the training pipeline and the inference pipeline.

But, there is a problem ❗
Problem
To build your training pipeline you need to have a significant amount of historical features in the store. Without enough historical data in your store, you cannot train a good predictive model.
You have 2 options to generate these historical features:
Wait a few days/weeks/months until your real-time feature pipeline generates enough data (what a bummer! 😞), or
Find another source of historical raw data (in our case trades), feed it to your feature pipeline and generate historical features. This operation is called feature backfilling, and it is definitely more appealing than just waiting 🤩
Let me show you how to do feature backfilling the right way.
Solution → Feature backfilling 🔙
To backfill historical features you first need to have access to raw historical data. In our case, Kraken has both
-
A Websocket API that serves trades in real-time, and
-
A REST API that serves historical trades for the time period we want.
Both data sources are consistent, meaning the trades that the websocket serves in real-time are the exact ones that are later on available as historical trades from the REST API.
Very important 🚨
All raw data (no matter whether it is live or historical) needs to be transformed into features using the exact same Python code.
Otherwise, the features that you will use to train your ML models might be slightly different that the ones you send to your model once deployed, and your model won’t work as you expect!
So, instead of re-writing the entire pipeline, you need to adjust the code in 2 places:
-
The ingestion step, to connect either to the live Websocket API or the Historical REST API, and
-
The serialization step, to save live features to the online store, and historical features to the offline store.

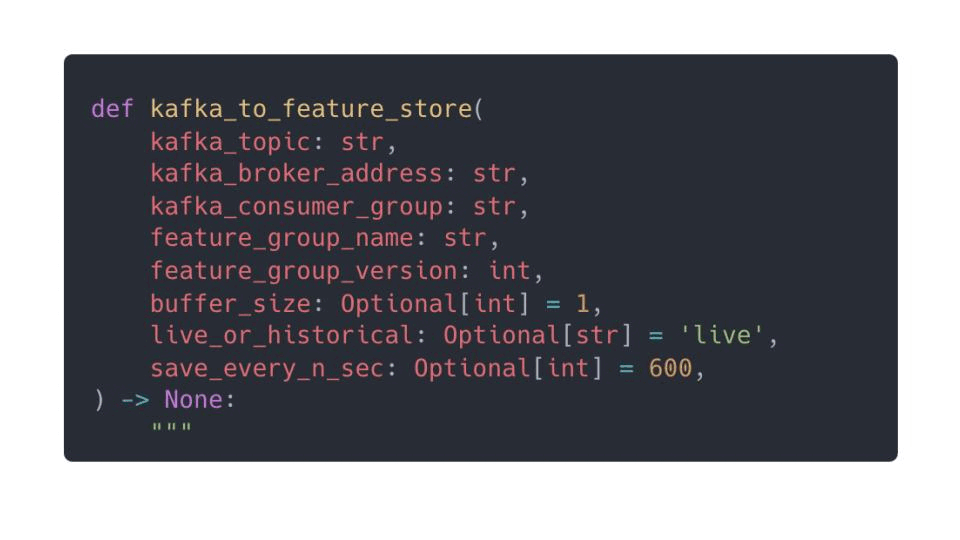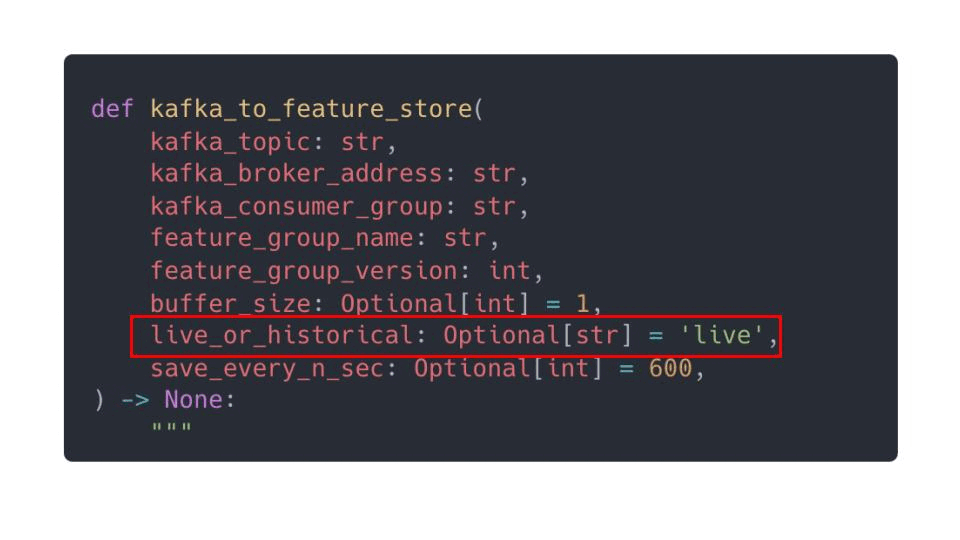
You can switch these 2 components based on your script input parameters, for example
-
To ingest either live or historical trades

-
To save features either to the online or the offline Feature Store


And remember, the transformation step is EXACTLY THE SAME, no matter if the feature pipeline runs with live data or historical data.

The secret sauce 🍅🔥
To implement this pipeline in Python you need a library that can help you read, transform and write data to Kafka in real-time.
My recommendation 💡
I recommend you use the open-source Python library Quix Streams, because
-
It is written in pure Python, so you avoid cross-language debugging, and your code integrates with the entire Python ecosystem (scikit-learn, TensorFlow, PyTorch…)
-
It has a Streaming DataFrame API (similar to pandas DataFrame) for tabular data transformations, so you don’t need to re-learn all the feature engineering techniques you already know for static data, and
-
It has a very dynamic and helpful Community on Slack. For example, yesterday I asked this question during my live coding session with students…
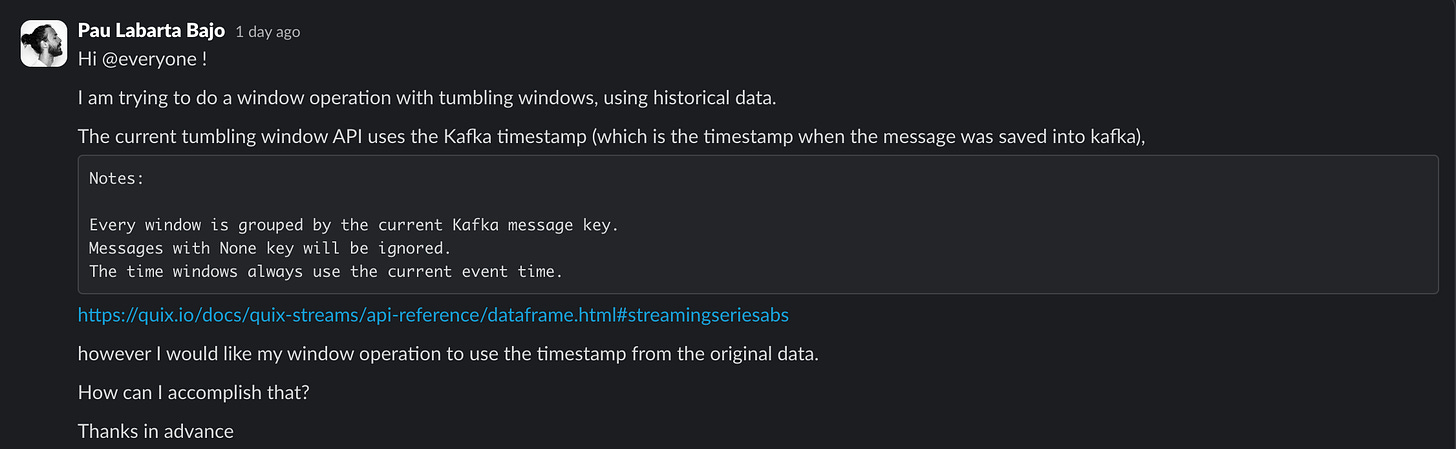
and I got the response I needed from Daniil, the Quix Streams Engineering Team Lead, on the same day. Beautiful ❤️



Now it is your turn 🫵
→ $ pip install quixstreams
→ Give Quix Streams a star ⭐ on Github to support the open-source
→ Join their Slack Community today to start riding the real-time ML wave 🌊
→ And get your hands-dirty!
Pau
