
How to scale a real-time ML system ⚡
Jul 01, 2024
For many real-world problems, ML model predictions need to be generated very fast. Otherwise, they are useless.
The problem 🤔
Let’s say you work as an ML engineer at a fintech startup, whose flagship product is a mobile app for online payments.
The company is still small, but nonetheless a critical problem you need to tackle from day 0 is the automatic detection of fraudulent transactions.

Speed and low latency are critical. Otherwise, you will detect fraud too late, and the predictions, no matter how precise they are, will be useless.

Moreover, you want your system to be scalable based on the volume of transactions your users generate per second. You aim to become a serious contender to VISA or MasterCard, so you want a design that can scale to over 65,000 transactions per second.

However, you don’t want high upfront costs 💸 and complex infrastructure to mange (well, who does? 😛), so the question is
How can you build a scalable real-time system to detect fraud, in a cost-effective way 💸❓
The solution 🧠
To make your system capable of
→ ingesting transactions, and
→ producing fraud notifications to end-users
at scale and fast you can use a streaming data platform (aka message bus), like Apache Kafka or, even better, Redpanda.

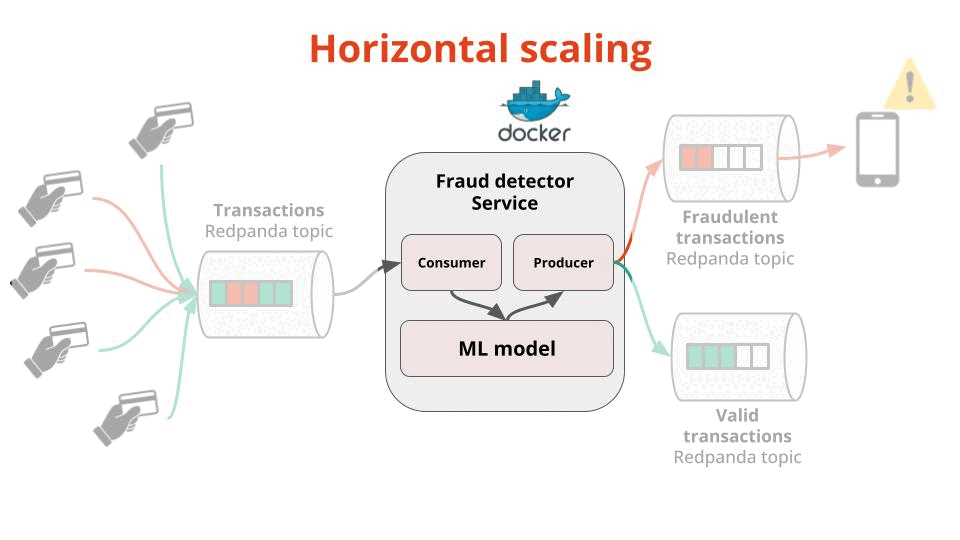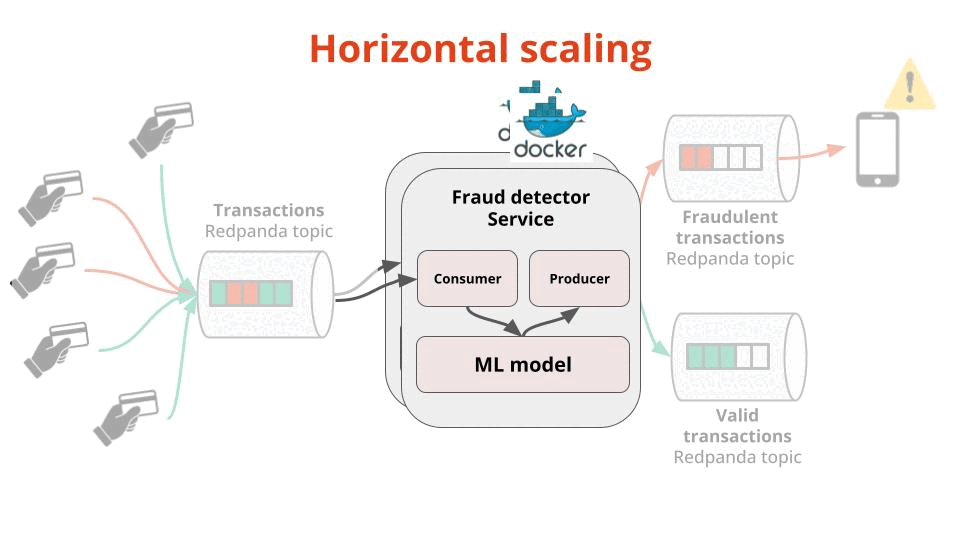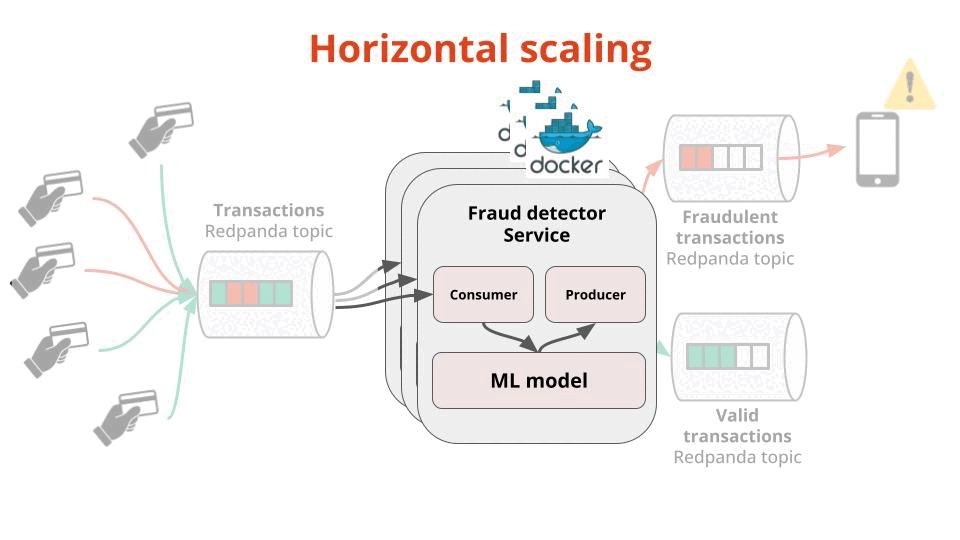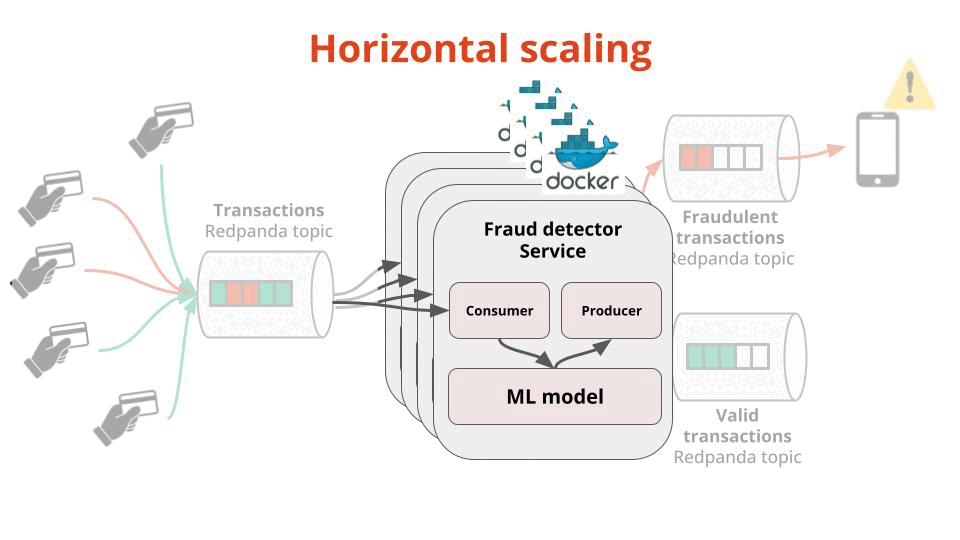
In this case your fraud detection service becomes a streaming application (e.g. a dockerized Python script written for example with Quix Streams) that continuously
-
Consumes incoming transactions from the Input topic
-
Scores them with an ML model asap, and
-
Produces them to the correct downstream topic, either
-
fraudulent transactions, that are consumed by your notification service to alert end users, or
-
valid transactions, that can be used by other downstream services.
-

What about scalability?
The scalability of the system depends on 2 things:
-
The number of messages your Redpanda cluster can process. This is something you can scale up and down with the number of brokers in your cluster, and the resources you allocate to them (CPU, memory…).

Image credits go to Redpanda

-
The number of transactions per second your Fraud Detector Service can process, which you can easily scale by spinning up more Docker instances of your service (aka horizontal scaling using consumer groups)

This is all fantastic, but what about the costs (both in time and $$$) of operating this system?
What about costs?
To run this system you need at least 2 things:
-
A compute platform, where your Fraud Detector Service runs. For example, Amazon EKS, Google Cloud GKE or Quix Cloud, and
-
A streaming platform, like Apache Kafka or Redpanda.
Apache Kafka or Redpanda 🤔 ?
Apache Kafka and Redpanda are the most popular open-source streaming data platforms. They both have the same API (the Kafka-API), but they have notable differences in how they are designed and operated.
Apache Kafka is built in Java and requires a complex mesh of services to run, while Redpanda is designed from the ground up in C++ and shipped as a single binary. Which means it is easier and cheaper to run. 🤑
My recommendation 💡
If you (or your company) wants to start building real-time ML systems, without investing a lot in upfront infrastructure costs, I recommend you try Redpanda Serverless.
→ With a few seconds you get your production cluster up and running (see this video).
→ You don’t need to manage any infrastructure, and
→ You only pay for what you use, so you go from 0 USD and scale based on your growth.
Looking forward to seeing what you build,
Talk to you next Saturday,
Pau
