
How to serve ML predictions 100x faster
Aug 12, 2024A very common way to deploy an ML model, and make its predictions accessible to other services, is with a REST API.
It works as follows:
-
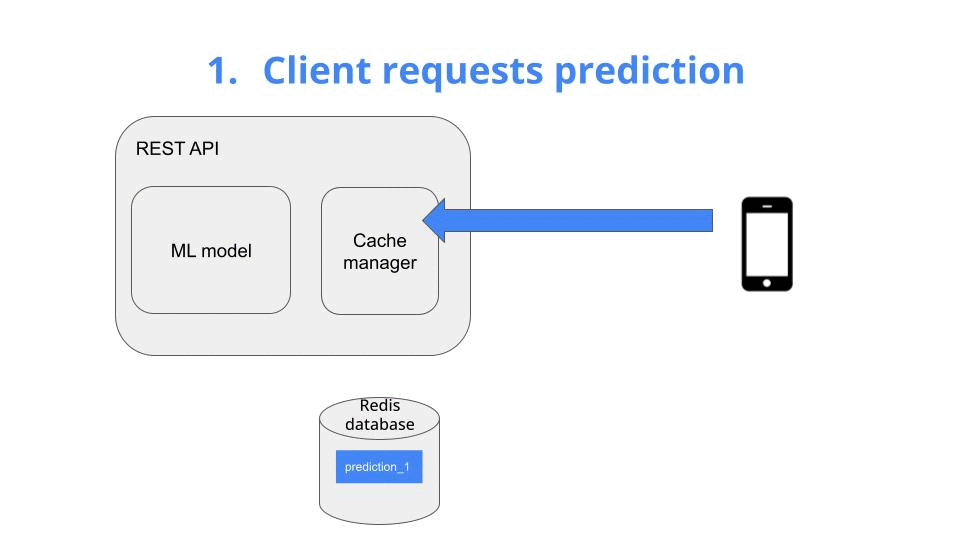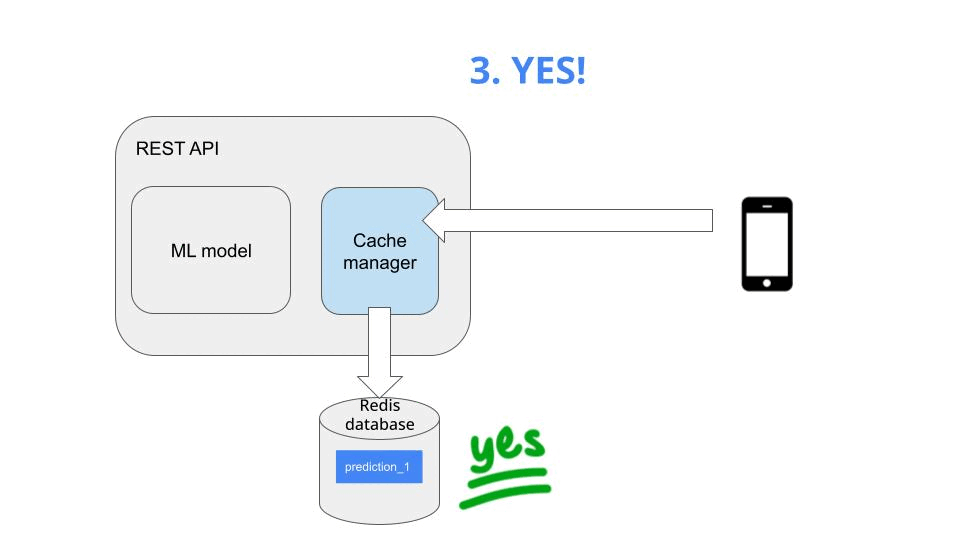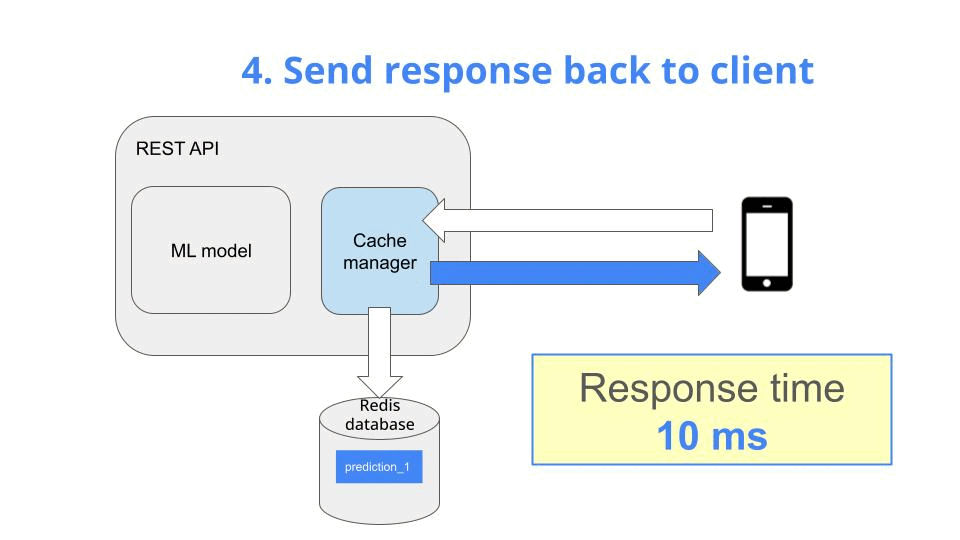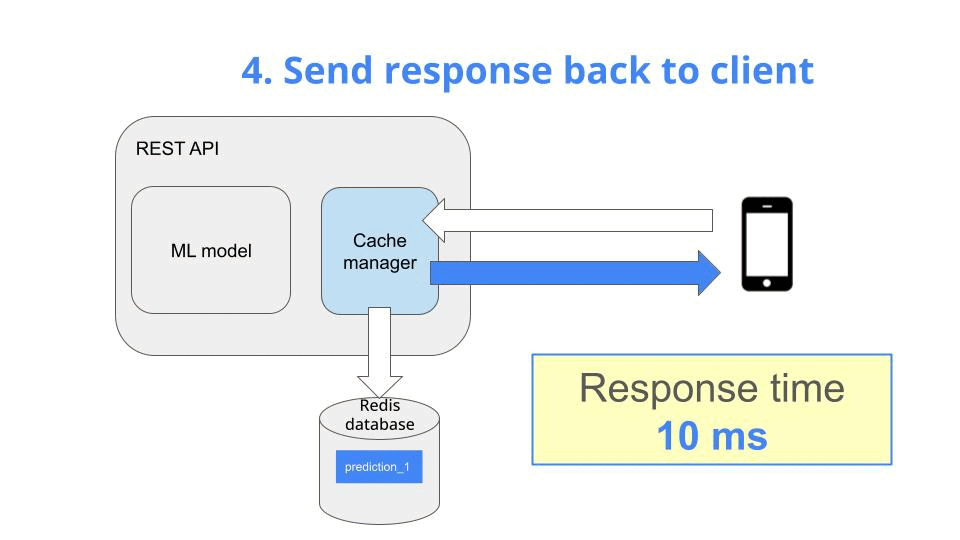
The client requests a prediction -> Give me the price of ETH/EUR in the next 5 minutes
-
The ML model generates the prediction,
-
The prediction is sent back to the client -> predicted price = 2,300 USD

This design works, but it can become terribly inefficient in many real-world scenarios.
Why?
Because more often than not, your ML model will re-compute the exact same prediction it already computed for a previous request.
So you will be doing the same (costly) work more than once 😵💫.
This become a serious bottleneck if the request volume grows, and you model is large, like a Large Language Model.
So the question is:
Is there a way to avoid re-computing costly predictions? 🤔
And the answer is … YES!
Solution 🧠
Caching is a standard technique to speed up API response time.
The idea is very simple. You add a fast key-value pair database to your system, for example Redis, and use it to store past predictions.
When the first request hits the API, your cache is still empty, so you
-
generate a new prediction with your ML model
-
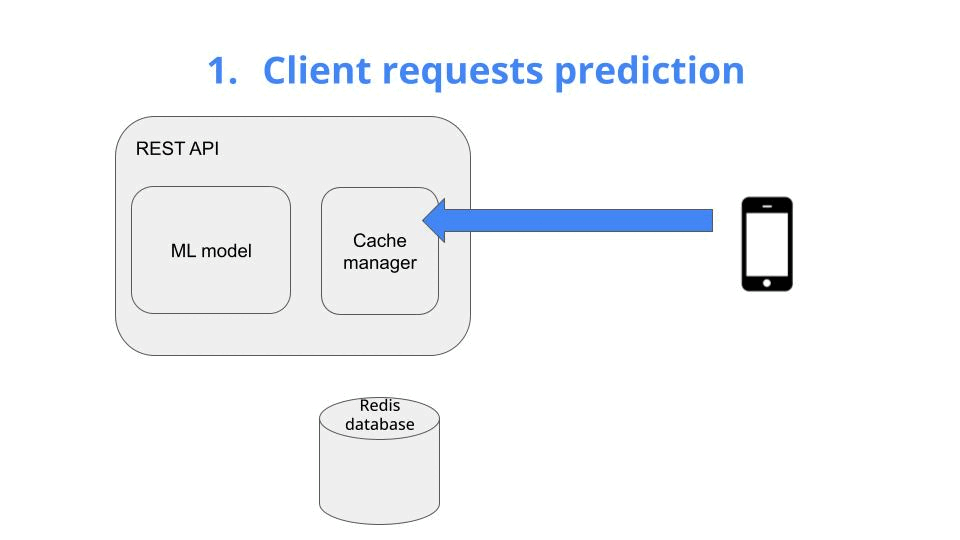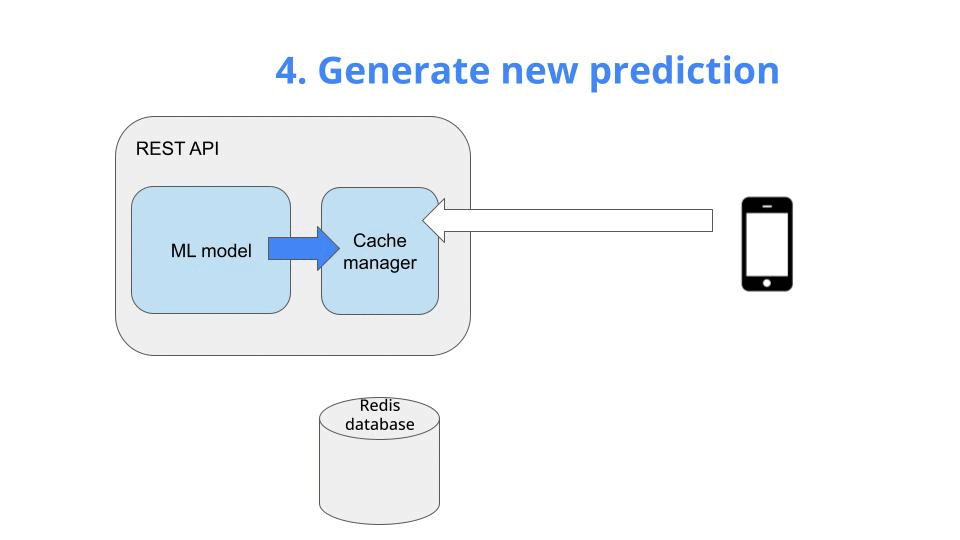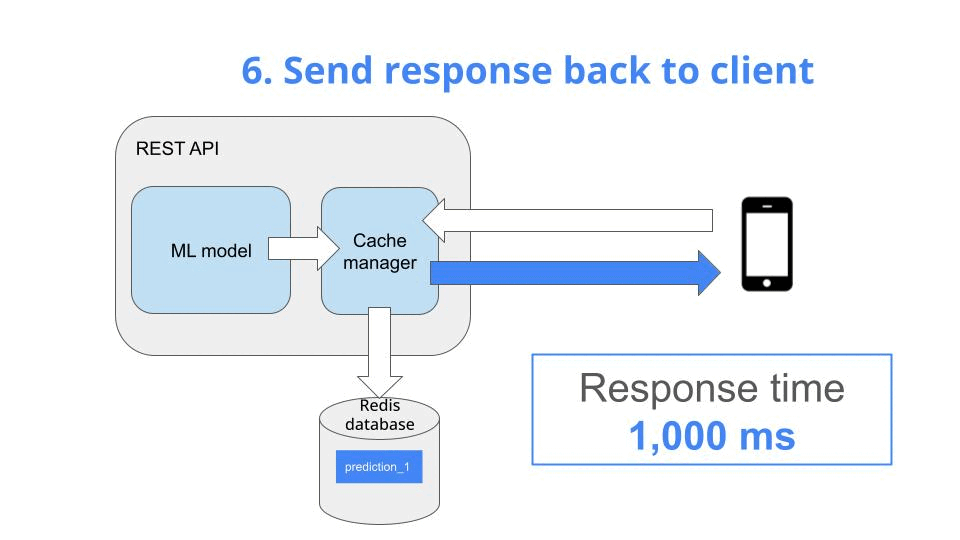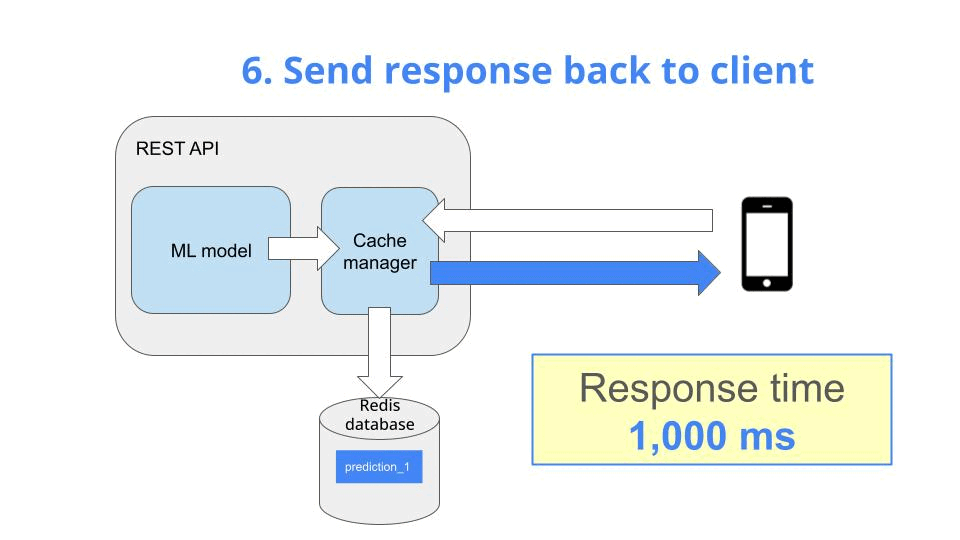
store it in the cache, as a key-value pair, and
-
return it to the client

Now, when the second request arrives, you can simply
-
load it from the cache (which is super fast), and
-
return it to the client

To ensure the predictions stored in your cache are still relevant, you can set an expiry date. Whenever a prediction in the cache gets too old, it is replaced by a newly generated prediction.
For example
If your underlying ML model is generating price predictions 5 minutes into the future, you can tolerate predictions that are up to, for example, 1-2 minutes old.
Example with full source code 👩💻👨🏽💻
In this repository that I created you will find a minimal Python implementation of a REST API with and without caching using FastAPI and Redis.
Git clone it, and run
$ make installto install all project dependencies inside an isolated virtual env.
You can spin up the FastAPI server without cache
$ make api-without-cacheor with cache
$ make api-with-cachesend a batch of requests and measure their response time
$ make requests
Time taken: 1029.59ms <-- new prediction
Time taken: 13.09ms <-- very fast
Time taken: 8.47ms <-- very fast
Time taken: 7.74ms <-- very fast
Time taken: 12.98ms <-- very fast
Time taken: 1020.92ms <-- new prediction
Time taken: 8.40ms <-- very fast
Time taken: 12.61ms <-- very fast
Time taken: 10.55ms <-- very fast
...
Wanna learn to build real-time ML systems, together? 🏗️🙋🏾♂️
On September 16th 150+ brave students and myself will start building, step-by-step a real-time ML system that predicts crypto prices.
After completing this 4-week program (+ A LOT of hard work on your end) you will know how to
-
Build modular and scalable real-time ML systems
-
For the business problem you care about
-
Using any real-time data source
-
Following MLOps best practices, for fast iteration and short-time-to-market.
And of course, we will implement REST API caching ⚡
Wanna know more about
Building a Real-time ML System. Together?
↓↓↓
Talk to you next week,
Peace and Love
